Auto-Vectorization and How to Make it Happen
What is Auto-Vectorization?
When you do the same operation on a set of numbers, (eg. adding the elements in two parallel arrays)
Instead of the following logic:
- Loop through the elements, start with element 0
- Store the first element of array 1 into a register on the CPU
- Store the first element of array 2 into a register on the CPU
- Add Array1element + Array2element
- Grab the next element
- Loop through the elements, start with element 0
- Store element 0 - 8 of array 1 into register on the CPU
- Store element 0 - 8 of array 2 into register on the CPU
- Add Array1elements + Array2elements
- Grab the next 8 elements
- compiler flags:
- -O3 is specified. This turns on a set of flags that compile with the “risk” of getting skewed results
OR - The individual flags for auto-vectorization are used like -ftree-vectorize and -fvect-cost-model
- -O3 is specified. This turns on a set of flags that compile with the “risk” of getting skewed results
- Assurance that none of the arrays overlap
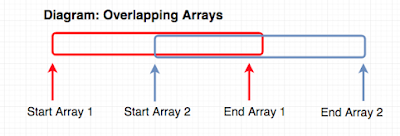
- Assurance that all of the arrays have their hardware words aligned. This means that elements of the arrays each take up a fixed amount of space, and you can expect where to find the next element. Although this is a little wasteful of space, it’s worth it so that it’s easier to jump to the next element.





Assembler Code Walkthrough on AARCH64 - Auto-Vectorized
Here’s the C code we’re going to vectorize:Let’s go through some Auto-Vectorized code and understand what’s going on in the assembly:
Go out there and Auto-vectorize!


Comments
Post a Comment